Création d'Interfaces Conversationnelles pour les Données Structurées : Guide Complet
À l'ère de la transformation numérique, les organisations sont submergées par des données structurées couvrant les transactions de vente, les enregistrements clients, les métriques opérationnelles, et bien plus encore. Cependant, la véritable valeur de ces données n'est réalisée que lorsqu'elles deviennent accessibles et exploitables pour les décideurs de l'entreprise. Les méthodes traditionnelles de requêtage des données structurées, telles que l'écriture de SQL ou la navigation dans des tableaux de bord complexes, créent souvent des barrières pour les utilisateurs non techniques. Les interfaces conversationnelles alimentées par l'intelligence artificielle redéfinissent la manière dont les utilisateurs interagissent avec les données, permettant des requêtes en langage naturel qui démocratisent l'accès et accélèrent les insights.
Ce guide complet fournit une approche étape par étape pour construire des interfaces conversationnelles robustes pour les données structurées, en tirant parti des dernières avancées en matière d'IA et de services cloud-native. Que vous soyez un ingénieur de données, un architecte de solutions ou un leader technologique, cet article vous équipera des connaissances et des meilleures pratiques pour concevoir, implémenter et optimiser les expériences de données conversationnelles.
Comprendre les interfaces conversationnelles
Les interfaces conversationnelles représentent un changement de paradigme dans l'interaction homme-machine. En permettant aux utilisateurs de communiquer avec les systèmes en utilisant un langage naturel—soit par texte soit par voix—elles éliminent la friction associée aux interfaces utilisateur graphiques (GUI) traditionnelles. Au lieu de naviguer dans des menus imbriqués ou de mémoriser la syntaxe des requêtes, les utilisateurs peuvent simplement demander, « Montrez-moi le chiffre d'affaires du dernier trimestre par région », et recevoir une réponse immédiate, contextuellement pertinente.
Interfaces basées sur des règles vs. interfaces alimentées par l'IA
Les interfaces conversationnelles peuvent être largement catégorisées en deux types : basées sur des règles et alimentées par l'IA.
Interfaces basées sur des règles : Ces systèmes fonctionnent sur des scripts prédéfinis, des arbres de décision et la correspondance de motifs. Bien que simples à implémenter, ils sont intrinsèquement limités. Les interfaces basées sur des règles peinent avec la variabilité et l'ambiguïté du langage naturel, échouant souvent à gérer des requêtes inattendues ou à s'adapter à de nouveaux schémas de données. Par exemple, un chatbot basé sur des règles pourrait ne reconnaître qu'un ensemble fixe de commandes, telles que « Montrez les ventes » ou « Listez les clients », et échouer face à des questions nuancées ou composées.
Interfaces alimentées par l'IA : En revanche, les interfaces conversationnelles alimentées par l'IA utilisent l'apprentissage automatique et le traitement du langage naturel (NLP) pour interpréter l'intention de l'utilisateur, extraire les entités pertinentes et comprendre le contexte. Ces systèmes peuvent généraliser une large gamme de requêtes, s'adapter à des modèles de données évolutifs et fournir des interactions plus personnalisées et efficaces. Par exemple, une interface alimentée par l'IA peut gérer des requêtes comme, « Comment nos trois principaux produits ont-ils performé dans le Nord-Est le mois dernier par rapport à l'année précédente ? »—générant automatiquement le SQL nécessaire et retournant une réponse concise et lisible par l'homme.
Les avantages transformateurs de l'IA dans les interfaces conversationnelles
L'intégration de l'IA dans les interfaces conversationnelles déverrouille plusieurs avantages clés :
Personnalisation : Les modèles d'IA peuvent adapter les réponses en fonction des profils utilisateurs, des interactions historiques et du contexte organisationnel, délivrant des insights à la fois pertinents et exploitables.
Efficacité : En automatisant la traduction du langage naturel en requêtes complexes, l'IA réduit le besoin de compétences spécialisées telles que le SQL ou la modélisation de données, permettant à un plus large éventail d'utilisateurs d'accéder et d'analyser les données.
Accessibilité : Les interfaces conversationnelles abaissent la barrière technique à l'entrée, rendant les données structurées accessibles aux analystes commerciaux, aux dirigeants et aux employés de première ligne—quelle que soit leur expertise technique.
Ces avantages conduisent collectivement à une meilleure littératie des données, une prise de décision plus rapide et une culture plus agile et axée sur les données au sein des organisations.
Configurer l'environnement
Avant de se lancer dans le développement d'une interface conversationnelle pour les données structurées, il est essentiel d'établir un environnement robuste et scalable. Tirer parti des services cloud-native accélère non seulement le développement mais garantit également la sécurité, la fiabilité et la facilité d'intégration.
Prérequis
Pour construire une interface conversationnelle moderne, vous aurez besoin d'un accès aux services AWS suivants :
Compte AWS : Un compte AWS valide avec des privilèges administratifs pour provisionner et gérer les ressources.
Amazon Bedrock : Le service géré d'AWS pour les modèles de fondation, offrant des capacités avancées de NLP et de langage naturel vers SQL (NL2SQL).
AWS Glue : Un service ETL (extract, transform, load) entièrement géré pour le catalogage des données et la gestion des métadonnées.
Amazon S3 : Stockage d'objets scalable pour les ensembles de données brutes et traitées.
Amazon Redshift : Un entrepôt de données et moteur de requête basé sur le cloud, haute performance.
Liste de contrôle pour la configuration de l'environnement
Un environnement bien architecturé est fondamental pour le succès de votre interface conversationnelle. Suivez cette liste de contrôle pour vous assurer que tous les composants sont en place :
Configuration du compte AWS : Configurez un compte AWS avec les permissions nécessaires, y compris l'accès à Bedrock, Glue, S3 et Redshift.
Accès à Amazon Bedrock : Activez l'accès aux modèles de fondation Bedrock et assurez-vous que votre compte est provisionné pour les capacités NL2SQL.
Création de bucket S3 : Créez un bucket S3 pour stocker vos ensembles de données structurées, tels que les enregistrements de ventes, les données d'inventaire ou les informations clients.
Catalogue de données AWS Glue : Configurez les crawlers AWS Glue pour scanner votre bucket S3, détectant automatiquement le schéma et créant des tables de base de données dans le catalogue de données Glue.
Provisionnement d'Amazon Redshift : Configurez un cluster Amazon Redshift—soit serverless soit provisionné—en vous assurant qu'il est connecté à votre catalogue de données Glue pour un requêtage fluide.
Rôles et politiques IAM : Établissez des rôles IAM avec des contrôles d'accès granulaires, accordant les permissions nécessaires pour que Bedrock, Glue, S3 et Redshift interagissent de manière sécurisée.
En préparant méticuleusement votre environnement, vous posez les bases d'une plateforme de données conversationnelle scalable, sécurisée et haute performance.
Construire l'interface conversationnelle : étape par étape
Avec votre environnement en place, vous pouvez maintenant procéder à la conception et à l'implémentation de l'interface conversationnelle. Les sections suivantes décrivent un flux de travail pratique, de bout en bout.
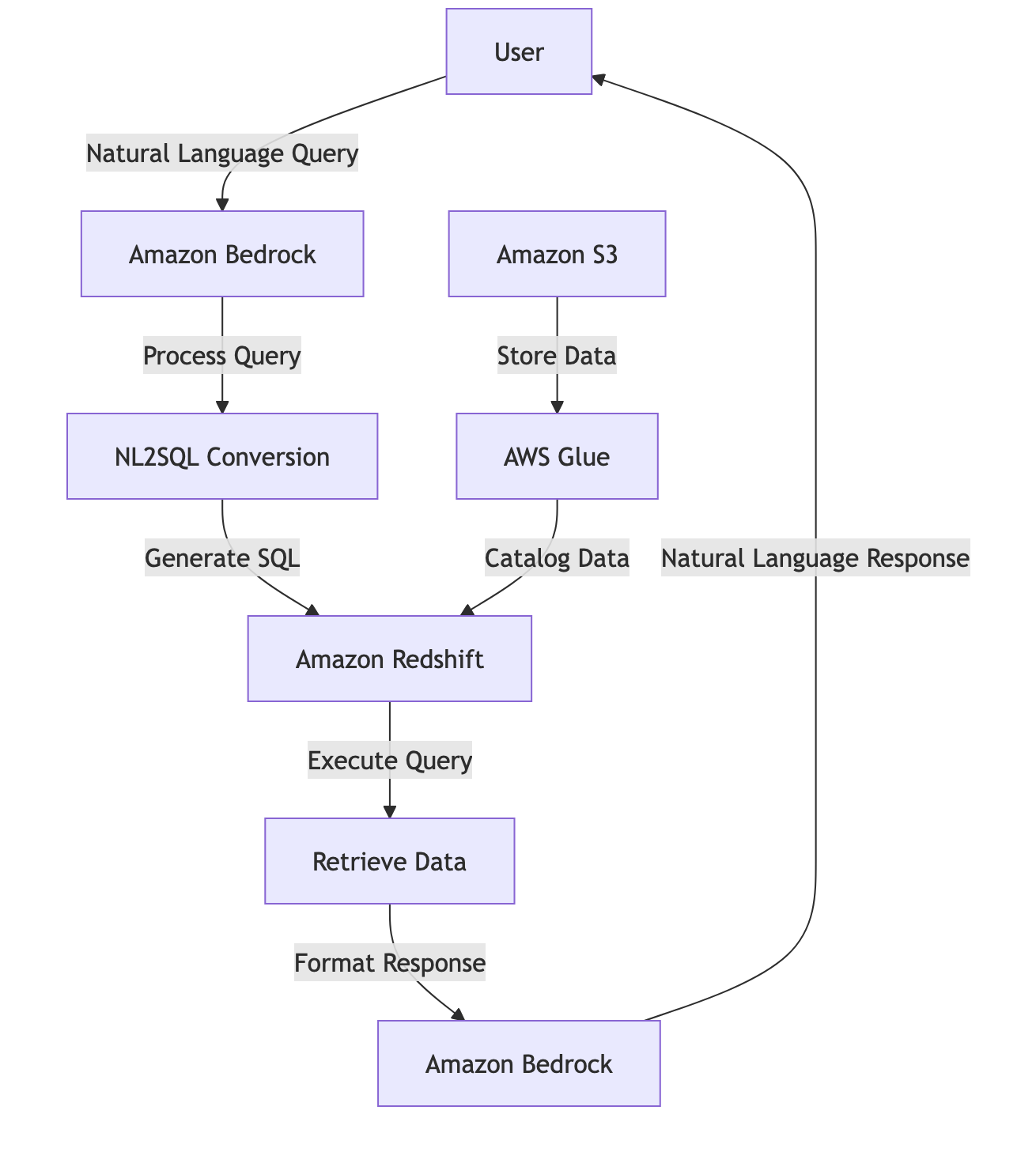
Étape 1 : Pipeline d'ingestion de données
La première étape consiste à s'assurer que vos données structurées sont accessibles à l'IA conversationnelle. Cela implique d'ingérer, de cataloguer et de préparer vos ensembles de données pour le requêtage.
Téléchargement des données : Utilisez des outils tels que Amazon SageMaker Data Wrangler, AWS CLI ou AWS SDKs pour télécharger vos ensembles de données (par exemple, les transactions de vente de commerce électronique) vers votre bucket S3 désigné. Assurez-vous que les données sont organisées dans une structure de dossiers logique pour une gestion facile.
Catalogage des données : Configurez les crawlers AWS Glue pour scanner le bucket S3, inférant automatiquement le schéma et peuplant le catalogue de données Glue avec des tables et des métadonnées. Cette étape est cruciale pour permettre aux services en aval de comprendre la structure et les relations au sein de vos données.
Configuration du moteur de requête : Provisionnez un espace de noms et un groupe de travail Amazon Redshift Serverless, ou utilisez un cluster existant, pour servir de moteur de requête principal. Connectez Redshift au catalogue de données Glue, permettant un requêtage fluide de vos ensembles de données ingérés.
Exemple illustratif :
Supposons que vous ayez un ensemble de données de ventes de commerce électronique stocké dans S3. Vous pouvez automatiser le processus de catalogage avec AWS Glue :
Copier# Pseudocode pour la configuration du crawler AWS Glue
glue_client.create_crawler(
Name='ecommerce-crawler',
Role='AWSGlueServiceRole',
DatabaseName='ecommerce_db',
Targets={'S3Targets': [{'Path': 's3://your-bucket/ecommerce-data/'}]}
)
glue_client.start_crawler(Name='ecommerce-crawler')
Ce processus garantit que vos données sont découvrables et requêtables par les services IA en aval.
Étape 2 : Configuration de la base de connaissances
Les bases de connaissances Amazon Bedrock servent de pont entre vos données structurées et le modèle IA, permettant des requêtes en langage naturel qui sont contextuellement conscientes de votre schéma de données.
Création du rôle d'exécution : Définissez un rôle d'exécution IAM avec des permissions pour Bedrock pour accéder aux ressources Redshift, Glue et S3. Ce rôle doit adhérer au principe du moindre privilège, accordant uniquement l'accès nécessaire.
Configuration de la base de connaissances : Utilisez l'API
CreateKnowledgeBaseou la console Bedrock pour établir une base de connaissances, reliant votre base de données Glue et le moteur de requête Redshift. Cette étape configure le modèle IA pour comprendre la structure et les relations de vos données.Synchronisation du schéma : Lancez des travaux d'ingestion pour synchroniser votre schéma de base de données avec le module NL2SQL de Bedrock. Cela garantit que le modèle IA peut générer avec précision des requêtes SQL qui reflètent votre modèle de données actuel, même lorsqu'il évolue au fil du temps.
En configurant méticuleusement la base de connaissances, vous permettez à l'IA d'interpréter les requêtes des utilisateurs dans le contexte de votre paysage de données unique.
Étape 3 : Développement de la logique conversationnelle
Au cœur de l'interface conversationnelle se trouve la logique qui interprète l'entrée de l'utilisateur, génère des requêtes et livre des réponses significatives.
Traitement du langage naturel : Lorsqu'un utilisateur soumet une requête—telle que « Quel a été le chiffre d'affaires des ventes en février 2025 ? »—Amazon Bedrock traite l'entrée, utilisant un NLP avancé pour extraire l'intention, les entités et le contexte.
Conversion NL2SQL : Le modèle IA traduit la requête en langage naturel en une instruction SQL syntaxiquement correcte, adaptée à votre schéma de données. Ce processus prend en compte les noms de tables, les types de colonnes et les relations, garantissant la précision et la pertinence.
Exécution de la requête : Le SQL généré est exécuté contre Amazon Redshift, récupérant les données demandées avec une haute performance et une scalabilité.
Génération de la réponse : Les résultats bruts de la requête sont traités par le modèle de langage, qui formate la sortie en une réponse claire et conviviale. Cela peut inclure un résumé, une visualisation ou des explications contextuelles.
Exemple de flux de travail :
Entrée de l'utilisateur : « Quel a été le chiffre d'affaires des ventes en février 2025 ? »
Traitement par l'IA : Bedrock interprète la requête, identifie la table pertinente et la plage de dates, et génère le SQL.
Exécution de la requête : Le SQL s'exécute sur Redshift, retournant les chiffres de vente pour la période spécifiée.
Livraison de la réponse : L'IA formate le résultat : « Le chiffre d'affaires des ventes pour février 2025 était de 1,2 million de dollars. »
Ce flux de travail fluide transforme la récupération complexe de données en une expérience conversationnelle naturelle.
Étape 4 : Test et itération
Des tests rigoureux et une itération continue sont essentiels pour livrer une interface conversationnelle de haute qualité.
Tests utilisateurs : Menez des sessions d'utilisabilité avec un groupe diversifié d'utilisateurs, observant comment ils interagissent avec l'interface et identifiant les zones de confusion ou de friction.
Collecte de feedback : Recueillez des feedbacks qualitatifs et quantitatifs, en vous concentrant sur des problèmes tels que les requêtes ambiguës, les réponses peu claires ou les attentes non satisfaites.
Amélioration itérative : Affinez les modèles NLP, les flux de conversation et les éléments d'interface utilisateur en fonction des feedbacks. Cela peut impliquer d'élargir les données d'entraînement, d'ajuster l'ingénierie des prompts ou d'améliorer la gestion des erreurs.
Surveillance des performances : Implémentez des analyses pour suivre les métriques clés telles que les taux de réussite des requêtes, les temps de réponse et la satisfaction des utilisateurs. Utilisez ces insights pour conduire une optimisation continue.
En embrassant une culture d'amélioration continue, vous assurez que votre interface conversationnelle reste intuitive, précise et alignée avec les besoins des utilisateurs.
Meilleures pratiques et considérations clés
Pour maximiser l'impact et la fiabilité de votre interface conversationnelle, adhérez aux meilleures pratiques suivantes :
Concevoir pour la clarté et la simplicité
Interactions guidées : Fournissez aux utilisateurs des sujets suggérés, des exemples de requêtes ou des modèles de commandes pour établir des attentes claires et réduire l'ambiguïté.
Requêtage incrémental : Décomposez les demandes complexes en étapes gérables, guidant les utilisateurs à travers des conversations multi-tours lorsque nécessaire.
Spécificité : Encouragez les utilisateurs à poser des questions précises et bien définies, et concevez l'interface pour demander des clarifications lorsque nécessaire.
Gérer l'ambiguïté avec grâce
Réponses de repli : Implémentez des mécanismes de repli robustes pour les requêtes que l'IA ne peut pas interpréter, offrant des suggestions utiles ou demandant une reformulation.
Compréhension contextuelle : Utilisez l'historique de la conversation et le contexte utilisateur pour désambiguïser les requêtes et maintenir la continuité à travers les interactions.
Autonomisation de l'utilisateur : Permettez aux utilisateurs de reformuler, affiner ou étendre facilement leurs demandes, favorisant un dialogue collaboratif.
Assurer la sécurité et la confidentialité des données
Contrôles d'accès : Appliquez des politiques IAM et AWS Lake Formation strictes pour régir qui peut accéder aux données et quelles informations peuvent être exposées via l'interface conversationnelle.
Masquage des données : Implémentez des garde-fous pour prévenir la divulgation d'informations sensibles ou personnelles dans les réponses.
Conformité : Adhérez aux normes de gouvernance des données organisationnelles et réglementaires, y compris la journalisation d'audit, le chiffrement et les politiques de rétention.
Favoriser la collaboration interfonctionnelle
Équipes multidisciplinaires : Impliquez des scientifiques des données, des designers UX, des ingénieurs logiciels et des parties prenantes commerciales tout au long du cycle de vie du développement.
Développement itératif : Adoptez des méthodologies agiles, incorporant des feedbacks continus et du prototypage rapide pour accélérer l'innovation et la réactivité.
En suivant ces meilleures pratiques, vous créez des interfaces conversationnelles qui sont non seulement puissantes et conviviales, mais aussi sécurisées, conformes et adaptables.
Conclusion
La convergence de l'IA et des interfaces conversationnelles révolutionne la manière dont les organisations déverrouillent la valeur des données structurées. En suivant une approche systématique—établir un environnement robuste, ingérer et cataloguer les données, configurer des bases de connaissances intelligentes, développer une logique conversationnelle sophistiquée et itérer à travers les feedbacks des utilisateurs—vous pouvez livrer des interfaces alimentées par l'IA, intuitives, qui autonomisent les utilisateurs à tous les niveaux.
Ces interfaces comblent le fossé entre la complexité technique et l'insight commercial, favorisant une culture de prise de décision et d'innovation axée sur les données. À mesure que les modèles d'IA et les services cloud continuent d'évoluer, le potentiel des expériences de données conversationnelles ne fera que s'étendre, offrant de nouvelles opportunités d'efficacité, de personnalisation et d'avantage concurrentiel.
Commencez votre voyage dès aujourd'hui en tirant parti d'Amazon Bedrock et de l'écosystème AWS pour construire des applications conversationnelles qui donnent vie à vos données structurées—transformant la manière dont votre organisation interagit avec l'information.
Ressources supplémentaires
Insight d'expert
« L'IA conversationnelle ne concerne pas seulement la technologie ; il s'agit de concevoir des expériences qui semblent naturelles et utiles pour les utilisateurs. L'intégration de l'IA avec les données structurées ouvre de nouveaux horizons pour l'intelligence commerciale et l'engagement des utilisateurs. »
— George Belsian, Architecte principal d'applications cloud, AWS
En embrassant ces stratégies et meilleures pratiques, les organisations peuvent exploiter le pouvoir transformateur de l'IA pour créer des interfaces conversationnelles qui rendent les données structurées accessibles, exploitables et impactantes—conduisant la collaboration, l'innovation et le succès commercial.
Ce guide a été rédigé avec l'aide des Experts AWS France de One Click Flare, votre Partenaire AWS à Paris.